在上一期《Prefab优化:预制体中的各种细节选择》中,我们针对UWA本地资源检测中和预制体相关的规则所涉及到的知识点进行了讲解。这些看似细小的知识点,很容易在大家的开发和学习过程中被疏忽,而长期的问题积累最终都会反映到项目的性能表现上。为此,我们将这些规则列出,并且以一个个知识点的形式向大家逐一解读。
本期,我们将主要面向粒子特效相关的检测规则:“特效播放时平均Overdraw率过高”、“特效播放时DrawCall峰值过高”和“特效总贴图内存过大”,以及新增加的材质规则“使用了Standard Shader的材质”。我们将力图以浅显易懂的表达,让职场萌新或优化萌新能够深入理解。
1、特效播放时平均Overdraw率过高

Overdraw,字如其名:过度绘制。在现实生活中我们的眼睛在观察环境时,如果环境内的物体前后摆放,那么堆叠部分就会被离我们视野最近的物体所遮挡而看不见。
在Unity中也是如此,对GPU而言,最理想的状态是忽略所有重合部分,只要绘制相机视野方向上最靠近的一层像素即可,但在实际应用时其实很难达成这种理想状态。场景中物体的重合会使得同一个像素点在一帧中会被绘制多次。这个绘制次数就是Overdraw,而我们这里所说的平均Overdraw率就是这一帧中每个像素点的平均绘制次数。
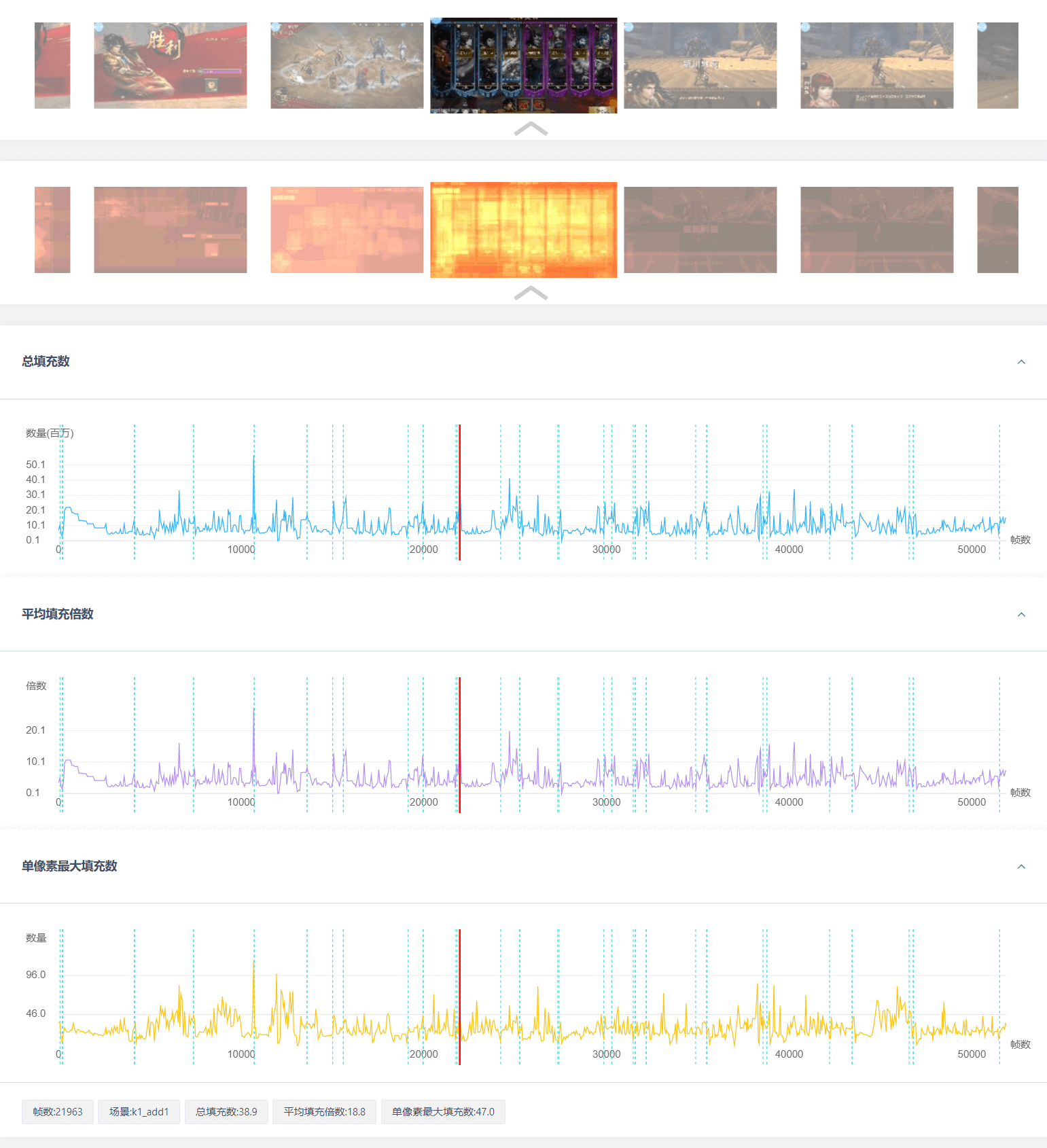
如图,这是UWA的真人真机测试报告内的Overdraw统计界面,Overdraw越高,截图就会越发偏向亮红色,乃至高亮。理论上Overdraw一定会存在,所有像素点都只绘制一次的达成难度和成本都会很高。
在Unity的特效播放中,在可接受范围内降低粒子特效效果不失为一种减少Overdraw的选择。当然我们也可以考虑在中低端机型上降低粒子数、同屏粒子数,通过做减法来减少Overdraw,比如只显示“关键”粒子特效或自身角色释放的粒子特效等;也可以通过尽可能降低粒子特效在屏幕中的覆盖面积来降低Overdraw,因为覆盖面积越大,层叠数也就越高,其渲染开销也会越大。
所以在本条规则找出这些粒子特效后,开发团队可以针对性地对这些粒子特效做出调整,为其做瘦身以达到性能与表现效果上的平衡。
2、特效播放时DrawCall峰值过高
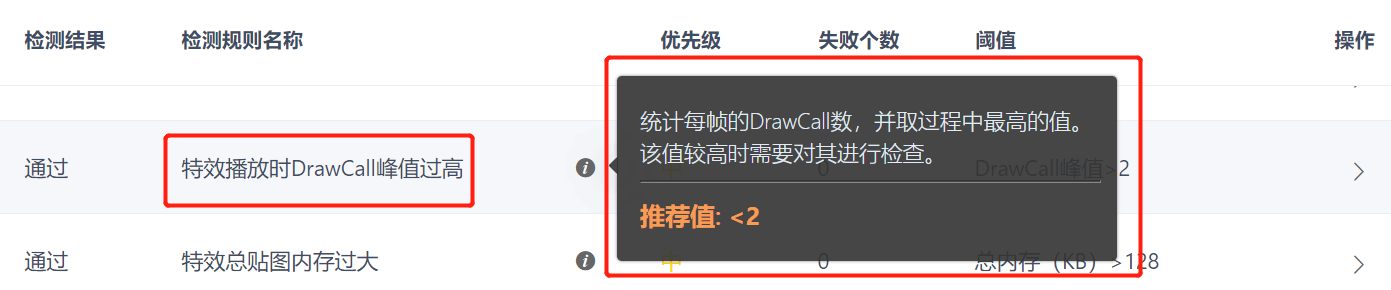
在Unity中,CPU发出命令让GPU执行渲染任务,这个过程就称之为一次DrawCall。
形象点理解的话,我们可以用现实中的巴拿马运河来类比,然后我们就能很好理解Unity中关于DrawCall的问题了。现实中,一艘船要通过巴拿马运河需要花费大量的时间和金钱,所以面对同一批货物,让尽可能少的船装载尽可能多的货物,是保证快速通过运河到达目的地的最有效方式。
那么在Unity中,CPU每发出一条命令,都需要做大量的前期准备,只有在数据、渲染状态以及相关设置参数等都检查无误装到“船上”后,这条命令才会被发出直至最终被GPU执行。
所以面对同样的渲染需求,如果分到很多个DrawCall上,那么CPU会消耗大量的时间和性能去用于前期的准备工作,从而形成了“CPU满负荷运转,GPU无所事事”的怪象。因此确保每一次DrawCall都高效运行迫在眉睫。
在Unity的粒子特效中,我们可以通过以下几种方式去进行DrawCall的优化:
- 开启GPU Instancing。使用GPU Instancing能节约大量的CPU运算开销。不过该功能的使用具有三个条件:
- 粒子系统的渲染模式为Mesh
- 使用支持GPU Instancing的Shader
- 在支持GPU Instancing的平台上运行
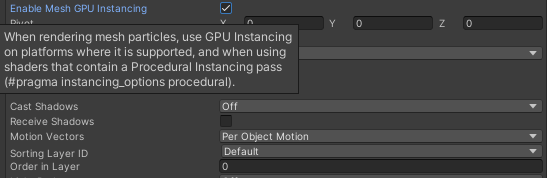
2. 开启动态合批,使用相同材质的粒子系统的网格会被合批。简单点来讲,会将大量的小网格合并为一张大网格,通过往“船上装更多的货物”来降低DrawCall。这里可以参考《关于Unity粒子系统优化,你可能遇到这些问题》
3. 降低特效效果,在可接受范围内由美术成员进行确认和修改,以更低的粒子特效需求去实现与原本近似的特效要求,不过这就很考验美术同学的功底和对特效展示的把控度。
所以开发团队可以活用本条检测规则,找出这些DrawCall峰值过高的粒子系统,针对性地进行DrawCall优化。
3、特效总贴图内存过大

在达成需要的粒子特效时,我们往往会配合使用多个粒子系统组件来实现一个复杂的特效展示。比如模拟极端的雷雪气候,我们就可能会用到诸如闪电,暴雪,强风,冰雹等多种不同的粒子系统。
但随着粒子系统组件数量的上升,在追求复杂粒子特效的同时,我们对整个粒子特效的把控很有可能会陷入“失控”的状态。比如加了太多的不同粒子系统(恨不得把所有和雷、雪相关的渲染效果全加上去);为实现一个效果添加了多种ParticleSystem;追求极致效果而是用了分辨率过高的贴图等。
这些都会使得粒子特效在最终成形的同时,也产生了本可避免的额外内存占用。所以本条规则聚焦“贴图资源”,对单个粒子特效下的贴图内存总和进行统计。
当相关资源超出阈值被统计出来后,开发团队可以进一步检查以判断贴图大小是否合理、贴图资源是否冗余以及特效展示上是否供大于求,从而更好地优化对应的粒子特效。
4、使用了Standard Shader的材质
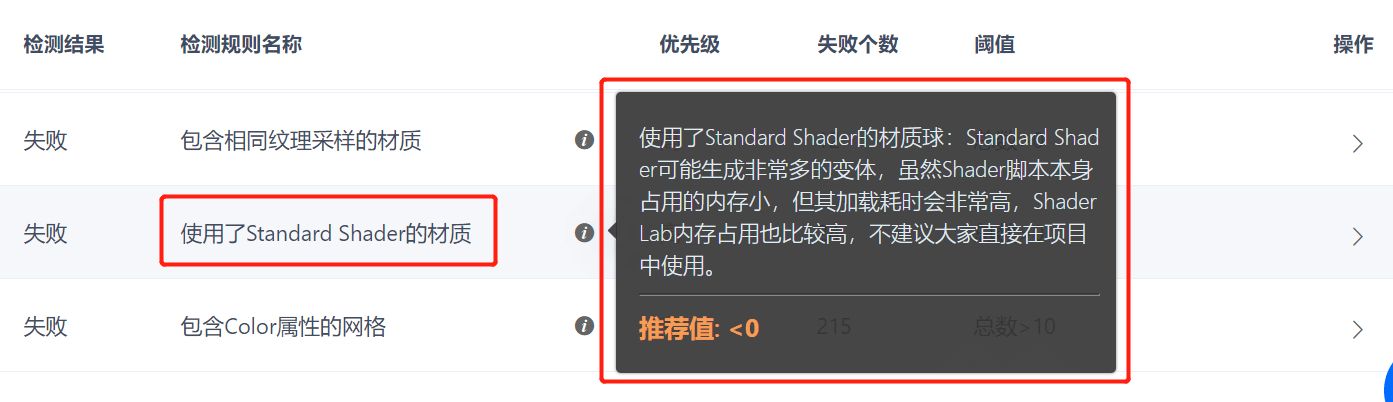
我们在之前的文章《【Shader优化】破解变体的“影分身”之术》中,对Shader和相关的变体知识进行了较为详细地介绍。这条规则就是针对项目中材质球使用的Shader进行检测。
如果材质球使用了标准着色器,而开发团队对相关的变体情况不敏感或者有所疏忽,就很有可能在实际使用时带入了大量的变体资源,量变引起质变,从而导致了加载耗时的上升和额外的内存开销。
所以开发团队可以活用本条规则,对筛选出来的材质资源进行检查,尽量不要使用Unity内置的Standard Shader,及早发现Shader可能带来的性能问题。
希望以上这些知识点能在实际的开发过程中为大家带来帮助。需要说明的是,每一项检测规则的阈值都可以由开发团队依据自身项目的实际需求去设置合适的阈值范围,这也是本地资源检测的一大特点。同时,也欢迎大家来使用UWA推出的本地资源检测服务,可帮助大家尽早对项目建立科学的美术规范。
万行代码屹立不倒,全靠基础掌握得好!
相关推荐
《UWA本地资源检测又更新|帮你把关Shader变体问题》
性能黑榜相关阅读
《那些年给性能埋过的坑,你跳了吗?》
《那些年给性能埋过的坑,你跳了吗?(第二弹)》
《掌握了这些规则,你已经战胜了80%的对手!》