《极致优化思想系列》是我用来收集一些不同目的诉求场景下的一些前人的精巧的极致设计思想,这些设计思路充满了艺术性,以此系列来作为敦促自我驱动不断进步之意。
《极致优化》的第一篇文章关注的便是“空间效率”这个最常见的criteria。而谈到空间的极致压榨利用,相信可能除了数据库便是操作系统了,由于数据库的技术暂时涉猎较少,故而本文先留白,留待日后不定期添加新的成员。
先引入Linux下的 段地址对齐概念
问题: 内存页frame是映射的最小单位,对于Intel80x86CPU来说,默认的页大小为4KB,也就是说要映射的物理内存大小和起始地址必须是4096倍数,虚拟地址空间中的起始位置和大小也要满足4096倍数。但这样一来,物理内存和虚拟内存segment的直接映射可能会导致较多的内部碎片,如何解决?
答:省着用,两相连段接壤部分按4KB为单位共享一个物理页,然后该页做两次映射,记录在虚拟内存—物理页对应关系表中。因为段地址对齐的缘故,导致现在各个段的虚拟地址就往往不是系统页面长度的整数倍了。
减小内部碎片的努力,以尽可能提升内存空间的使用效率:
1.目标文件到可执行文件的链接过程中:多同名section段合并
2.可执行文件到虚拟空间VMA映射的装载过程:相同权限RWX的section相连排布,提出segment
3.虚拟空间VMA到物理内存页的对应过程运行:相连segment的接壤部分共用一个物理页4KB ,而这个物理页多做一次映射记录到“虚拟内存—物理页对应关系表中”。
注:只需要多付出一个目录项的空间便可以使用上一个VMA剩下的空间,这也导致0x1000不再作为虚拟空间分配的基础单位了,虚拟空间segment起始地址开始出现0x99E8这种地址,当然段起始地址还是要以4B为单位的,即可被4整除。
Linux采用混合多重索引结构,将将文件所占用盘块block的盘块号直接或间接地存放在该文件索引节点Iinode的地址项中,在Linux中索引节点被称为inode,大小128B,记录一个block要花费4B(32位系统),在EXT2/3系统规定inode中含有12个直接地址项,1个一次间接项(指向一重索引表),1个二次间接项(指向二重索引表),1个三次间接项(指向三重索引表)。
EXT2/3这种混合多重索引结构是种经典的平衡策略(取长补短,取直接块索引的快速,取间接索引的大容量),原因如下:
1. 直接寻址:因为Linux系统中以中小型文件流为主,几十KB很常见,这时采用直接寻址即采用inode中的12个直接地址项,可以有效减低IO次数,这也是这些块被称为直接块的原因;
2. 一次间接寻址:当文件达到几百KB时,Linux提供一次间接寻址,顶层索引节点中存放的是直接块的块号对应表;
3. 多次间接寻址方式,依次类推。
从上面分析可以看到,混合索引结构对于小文件保证快速访问,对于大文件也能提供较好的支持。是属于经典的时间-空间效率“鱼和熊掌兼得”的好设计。
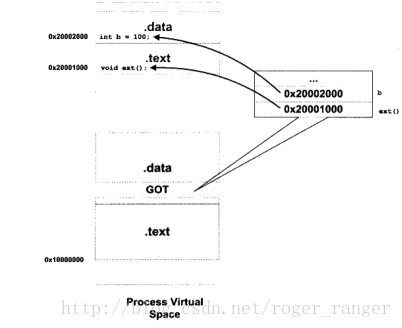
Linux为了尽可能让共享模块中的指令集被复用,显然需要将这些复用的指令集合转换成不收具体装载位置限制的地址无关性代码。所以实现思路是将把指令中需要被修改的部分分离出来,跟需要被修改的RW数据段放在一起,这些RW权限的段是每个进程都需要有一个副本的,而RX权限的纯无需修改.code段则可以被复用,这种技术成为地址无关代码(PIC, Position-independent Code)。也是Linux区别于Windows的一个重要特征,也是Linux能比Windows对机器硬件需求更低的诸多小设计之一。
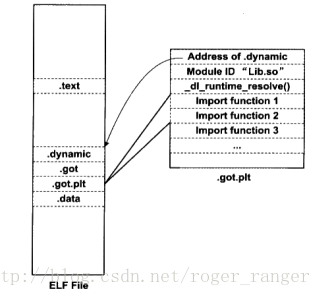
显然地址无关技术增加对程序的遍历编译次数,故而在前期编译阶段Linux要花费更多的时间用于区分代码中的装载地址无关性代码和相关性代码。PIC技术实现的关键是通过引入GOT中转表来将代码段的装载地址相关性通过转移到GOT表上来实现代码段的地址无关性。类似于化学反应中主动还原反应,即船体下挂铝块以减少船体的腐蚀情况。而Linux采用PIC技术不仅可以节省磁盘空间,更可以减少同库文件在内存中副本数,并增加内存缓存体系的命中效率。
未完待补……